
임정환 모티프테크놀로지스 대표가 10일 서울 강남구 조선팰리스에서 열린 ‘레노보 테크데이’에서 sLLM 모델 ‘모티프 2.6B’를 소개하고 있다.(사진=윤정훈 기자)
임정환 모티프테크놀로지스 대표는 “sLLM은 저전력으로 구동되고 슈퍼컴퓨터 없이 운영이 가능해 비용 효율성이 매우 높아 실제 산업 현장에서 다양한 적용이 가능해 성장 잠재력이 매우 크다”면서 “이번에 선보인 모티프2.6B를 활용해 우리 일상에서 사용할 수 있는 온디바이스 AI, 에이전틱 AI 모델로 발전시켜 나갈 것”이라고 강조했다.
이번에 모티프가 공개한 sLLM은 모회사인 모레가 설립 초기부터 추구해온 GPU 자원의 효율적 사용과 클러스터링 SW 최적화 기술을 기반으로 모티프에서 개발한 경량화된 고성능 AI모델이다.
모레는 작년 12월 오픈AI GPT-4의 한국어 성능을 능가하는 1020억 매개변수 규모의 한국어 특화 고성능 LLM을 개발했고, 올해 2월부터는 법인을 독립해 AMD GPU 기반의 AI모델 개발에 힘써왔다.
모티프는 26억개 매개변수로 구성된 모티프 2.6B가 글로벌 sLLM과 비교해도 성능이 뛰어나다고 밝혔다.
각 개발사가 공개한 테크니컬 리포트의 점수와 설정값을 동일하게 적용해 벤치마크 점수를 산출한 결과 ‘모티프 2.6B’는 70억 개 매개변수를 가진 미스트랄 7B 대비 134%의 성능을 보였다. 특히 고성능을 요하는 고난도 수학 및 과학, 코딩 능력에서 상대적으로 높은 점수를 기록했다. 동급인 1B~3B 모델과의 비교에서도 구글 젬마1(2B) 대비 191%, 메타 라마 3.2(1B) 대비 139%, AMD 인스텔라(3B) 대비 112%, 알리바바 큐원 2.5(3B) 104%로 우수한 성능을 보였다.
‘모티프 2.6B’는 문맥 이해 능력을 강화한 점이 가장 큰 기술적 특징이다. 잘못된 문맥을 참고해 부정확한 문장을 생성하는 오류를 줄이고, 필수적인 핵심 문맥에 집중하도록 설계했다. 트랜스포머(Transformer) 구조의 핵심인 어텐션(Attention) 기술을 보다 정교하게 활용해 좀 더 적절하게 단어를 사용할 수 있는 구조를 적용했다.
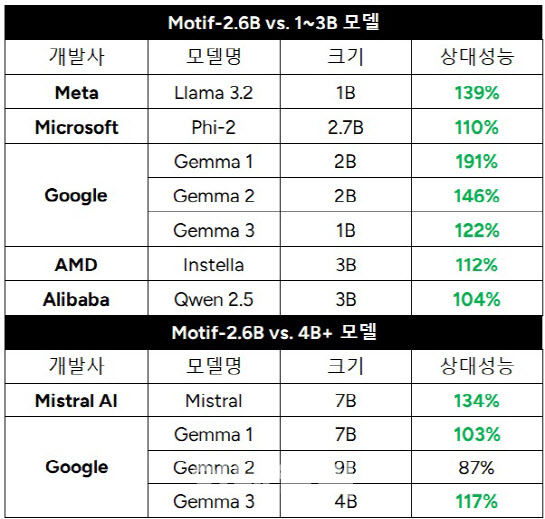
모티프가 만든 sLLM 모델을 구글, MS, 알리바바 등의 동급 이상의 모델과 성능을 비교한 표(사진=모티프테크놀로지)
조형근 모레 최고전략책임자(CSO)는 “모레는 엔비디아 의존 없이 AMD와 협력해 효율적인 AI인프라를 만들어서 검증을 마쳤다”며 “많은 기업이 저희의 인프라 SW와 기술을 활용해 고효율의 경제성 있는 AI를 만들어 주길 바란다”고 말했다.