© News1 김초희 디자이너
국내 5개 민간 컨소시엄이 경쟁하는 '독자 인공지능(AI) 파운데이션 모델' 사업의 개발 마감 기한이 약 한달 남았다.
그간 우리 기업이 두각을 드러내지 못한 수천억 개 매개변수(파라미터) 모델군이 목표다. 모델 규모를 키우더라도 실질적인 성능을 위해선 양질의 데이터가 받쳐줘야 한다. 현 시점에도 5개 컨소가 데이터 정제·학습에 열을 올리는 이유다.
21일 과학기술정보통신부에 따르면 사업의 1단계 평가가 내년 1월 1일부터 15일까지 진행된다. 컨소시엄들은 다음 달 중으론 개발을 마쳐야 한다.
사업은 글로벌 주요 파운데이션 모델의 성능 95% 이상을 우리 기술로 구현해 보는 게 목표다. 학습 가중치가 공개된 기존 모델을 개량해선 안 되고, 밑바닥부터 설계(프롬스크래치)해야 한다.
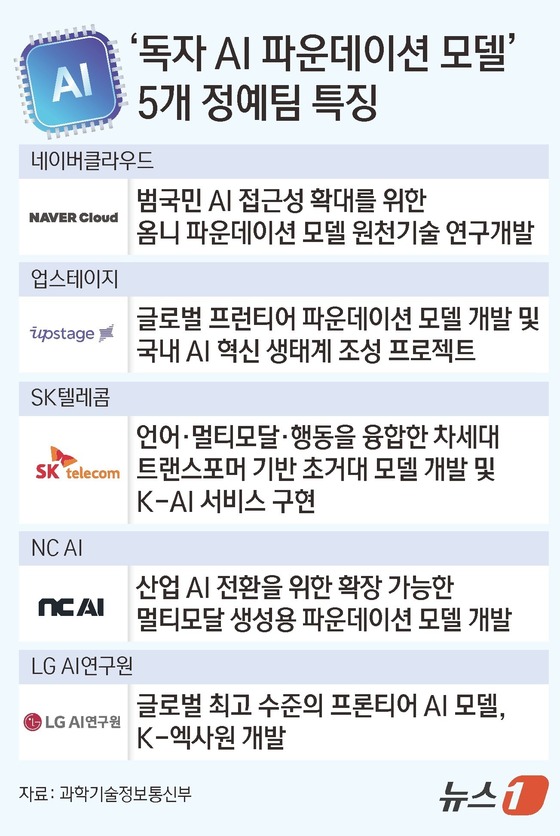
정부는 올해 8월 기존 개발 업력, 계획서 등을 검토해 유망 5개 컨소시엄을 추렸다. 네이버클라우드·업스테이지·SK텔레콤(017670)·엔씨 AI·LG AI연구원이 이끄는 컨소시엄이다.
네이버를 제외한 대다수 컨소는 최소 1000억 개 파라미터(매개변수) 모델을 목표로 제시했다. 특히 AI 개발이 본업이 아닌 SKT는 컨소 중 최대 수준인 5000억 파라미터를 제시해 주변을 놀라게 했다.
다만 양질의 정제 데이터가 없으면 아무리 파라미터 규모를 키워도 성능상의 한계가 생긴다. 업스테이지·엔씨·SKT가 법률·방송 등 다양한 데이터 제공업체를 컨소에 영입한 이유다. 정부 역시 데이터 공동구매 등을 통해 지원하고 있다.
이 부분에선 프롬스크래치 경험이 풍부한 LG와 네이버가 여유로운 모습을 보인다. 이미 기존 개발을 통해 정제 데이터를 많이 확보해 둬서다. 실제로 LG는 학습 데이터보단 향후 모델 확산에 초점을 두고 컨소를 구성했다.
다만 1차 평가는 유독 일정이 촉박해, 대다수 컨소가 개발을 마무리하지 못하고 지금도 데이터 학습에 여념이 없는 모양새다. 컨소 참여사로부터 필요 데이터를 다 못받은 곳도 있다고 한다.
이 밖에도 SKT·네이버 컨소로부터 엔비디아 B200·H200 등 GPU를 빌린 업스테이지·엔씨·LG 컨소 3곳은 초기 세팅에서 지연을 겪어 출발이 늦어졌다. 두 회사 대비 GPU 최적화, 기술적 연결, 시스템 정합성 등 대비가 부족해서다. 이들은 올해 8월 하순이 돼서야 모델 학습에 착수할 수 있었다.
업계 관계자는 "1차 평가는 실질적으로 개발 기간이 4개월 정도"라며 "다음 달 중 개발을 마감해야 하지만, 파인튜닝이나 경량화에 본격 착수하지 못한 곳도 있을 것"이라고 말했다.
한편 과기정통부로선 모두를 만족시킬 공정한 평가 기준을 마련해야 해 고민이 크다. 컨소마다 1차 결과물의 정량적 목표, 접근 방식 등이 상이해서다.
특히 네이버는 나머지 컨소와는 달리 1차부터 멀티모달 기능도 담은 '옴니 파운데이션 모델'을 내놓을 계획이다. 언어모델에 그치지 않고, 산업 현장에 적용될 수 있는 피지컬 AI까지도 염두에 두고 있어서다.
평가가 언어성능 중심으로 이뤄진다면 네이버 컨소에는 불리한 상황이 될 수도 있다. 네이버의 1차 모델 매개변수 규모는 컨소 중 최소 수준인 140억 개로 알려졌다.
다른 업계 관계자는 "비교적 개발 이력이 짧은 SKT가 파라미터 체급으로 밀어붙이면 네이버를 앞지르는 상황이 될 수도 있다"며 "대다수 컨소가 언어모델 중심으로 1차에 임하는 걸로 안다. 네이버로선 억울한 상황이 될 수 있다"고 말했다.
legomaster@news1.kr









