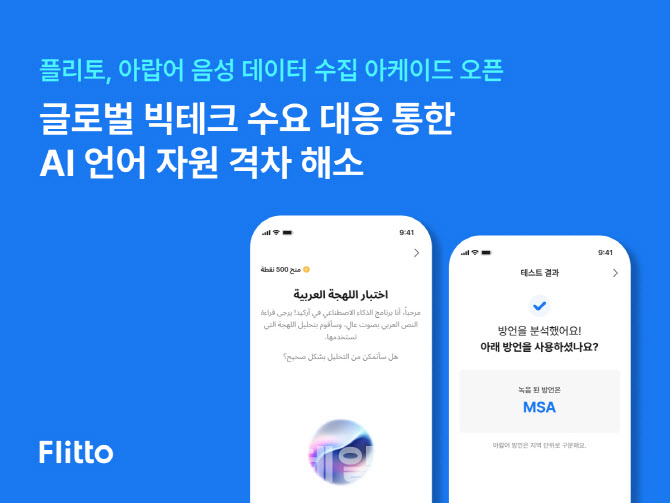
플리토 아랍어 음성 데이터 수집 프로젝트로 글로벌 AI 언어 격차 해소(사진=플리토)
플리토는 자사 모바일 애플리케이션 내 음성 데이터 수집 기능인 ‘아케이드’를 활용해 아랍어 음성 데이터 수집 이벤트를 운영하고 있다. 이용자가 제시된 문장을 읽고 발음을 녹음하면, AI 시스템이 이를 자동 분석해 발화 음성의 방언 유형을 판별하는 방식이다. 방언 유형이 불분명할 경우에는 추가 문장을 제시해 재참여를 유도함으로써 데이터 정확도를 높이도록 설계했다.
플리토는 최근 글로벌 빅테크 기업을 중심으로 다국어 음성 데이터 수요가 꾸준히 증가하면서 실제 프로젝트 요청도 확대되고 있다며, 이번 프로젝트를 통해 향후 잠재 수요에 선제적으로 대응한다는 계획이다.
회사 측은 이번 아랍어 음성 데이터 수집을 통해 단순 음성 정보뿐 아니라 발화자의 패턴, 억양, 어휘 선택 등 언어적 다양성이 반영된 정교한 학습용 데이터 구축이 가능할 것으로 기대하고 있다. 이를 통해 언어 자원 편차에 따른 AI 학습 편향을 완화하고, 실사용 환경에서도 높은 인식률을 구현할 수 있는 데이터셋으로 발전시킨다는 방침이다.
이정수 플리토 대표는 “아랍어는 전 세계 4억 명 이상이 사용하는 주요 언어지만, 사용 인구에 비해 AI 학습용 데이터가 부족한 저자원 언어에 속한다”며 “이번 프로젝트를 통해 아랍어 고유의 특성과 실제 사용 맥락을 반영한 데이터 구축으로 글로벌 AI 모델의 아랍어 인식 품질을 한층 끌어올리는 데 기여하겠다”고 말했다.









