개인정보보호위원회는 이에 대해 “생성형 AI 서비스마다 개인정보 보호 수준이 다르며, 같은 서비스라도 설정에 따라 달라질 수 있다며 서비스별 정책을 확인하는 것이 바람직하다”고 조언한다. 개인정보위는 19일 이를 포함해 생성형 AI 이용 과정에 대한 자세한 조언 내용이 담긴 ‘생성형 AI 서비스 이용자를 위한 개인정보 보호 가이드’를 발간했다.

'생성형 AI 서비스 이용자를 위한 개인정보 보호 가이드' 주요 내용 (사진=개인정보보호위원회)
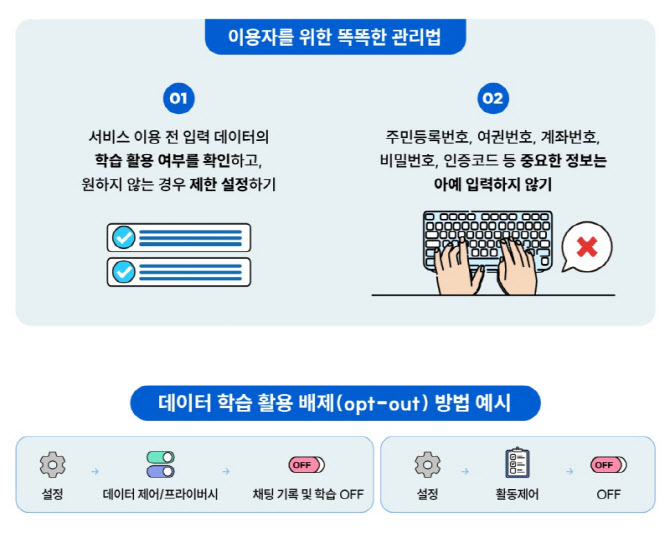
구체적으로 가이드라인에는 ‘생성형 서비스 이용 전 입력 데이터의 학습 활용 여부를 확인하고, 원하지 않는 경우 제한 설정하기’, ‘주민등록번호, 여권번호, 계좌번호, 비밀번호, 인증코드 등 중요한 정보는 아예 입력하지 않기’ 등의 조언이 담겼다.
특히 옵트아웃(학습활용 거부) 및 대화 기록 저장·삭제 설정 등 이용자가 직접 확인하고 통제할 수 있는 기능을 함께 안내했다.
개인정보위는 한번의 대화에서 안전해보이더라도 “AI 서비스는 이용 과정에서 텍스트뿐 아니라 이미지나 음성 업로드를 통해서도 대화와 단서가 계속 축적된다”면서 “한 번의 입력으로는 식별이 어려워 보여도, 이처럼 누적된 정보들이 결합되면 특정 개인이 식별될 수 있으므로 주의해야 한다”고 조언했다.
아울러, 복잡한 기술 구조나 법률 해석 위주의 설명에서 벗어나 △입력 내용의 AI학습 활용 여부 △업무 관련 자료 입력 시 주의사항 △외부 서비스 연동 시 안전성 등 민원 사례와 언론 보도 분석을 통해 도출한 8가지 주요 질의에 대한 답변과 함께 관리방법을 제시했다.
‘AI 프라이버시 민·관 정책협의회’ 정보주체 권리 분과장을 맡고 있는 윤혜선 한양대 교수는 “생성형 AI가 일상화되었으나 이용자가 개인정보 처리 과정을 명확히 파악하기는 어려운 실정”이라며, “이번 가이드가 학습 활용 여부, 기록 삭제 등 주요 궁금증을 해소하고 이용자가 직접 자신의 개인정보를 점검하고 관리하는 첫걸음이 되기를 바란다”고 말했다.
송경희 개인정보위 위원장은 “그간 생성형 AI 서비스의 복잡한 작동 방식 뒤에 가려져 있던 개인정보 처리 구조를 국민이 보다 쉽고 정확하게 이해할 수 있도록 하는 것이 이번 가이드의 핵심”이라며, “앞으로 개인정보위는 이용자가 AI의 편의성을 누리면서도 필요시 옵트아웃 등 권리 행사를 통해 자신의 정보에 대한 통제권을 실질적으로 행사할 수 있도록 지원하고, 안전하고 신뢰할 수 있는 AI 이용 환경 조성에 정책적 역량을 집중해 나갈 것”이라고 말했다.