노타는 피지컬 AI 구현의 핵심인 ‘비전-언어-행동 모델(VLA)’을 퀄컴의 최신 엣지 AI 디바이스 환경에서 효율적으로 구동할 수 있는 최적화 기술을 입증했다고 29일 밝혔다.
이번 성과는 GPU(그래픽처리장치) 서버 중심의 고연산 AI 모델을 가벼운 엣지 디바이스 단독 환경으로 이식하는 동시에, 실질적인 속도 개선까지 증명해냈다는 점에서 업계의 주목을 받고 있다.
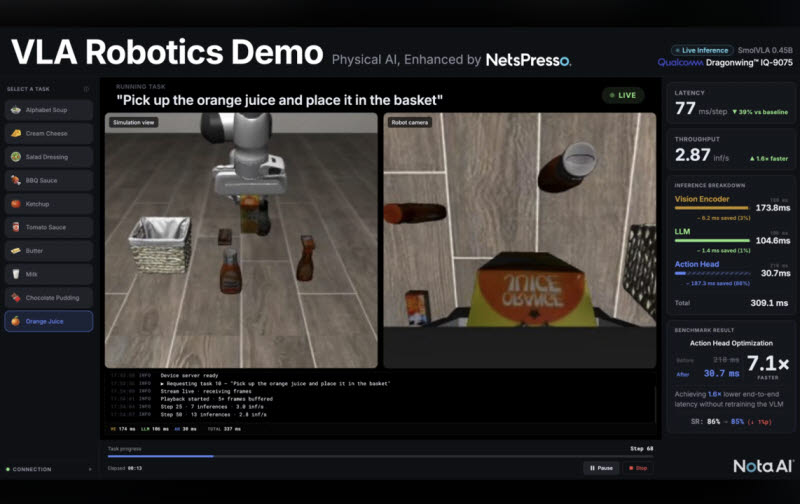
VLA 시연 데모(사진=노타)
피지컬 AI는 AI가 카메라 등 센서를 통해 실제 물리적 환경을 인식하고, 인간의 명령을 이해한 뒤 이를 실제 ‘행동’으로 연결하는 기술이다. 로봇, 스마트 제조, 물류 등 산업 전반의 디지털 전환을 이끌 핵심 기술로 꼽힌다.
특히 시각 정보와 언어 명령을 동시에 처리해 로봇의 움직임을 만들어내는 VLA 모델이 핵심 탑재되지만, 이미지·언어·행동 생성을 동시에 처리해야 해 연산량이 막대하다는 단점이 있었다. 이 때문에 기존에는 클라우드나 고성능 GPU 서버 의존도가 높아, 즉각적인 반응이 필수적인 로봇·산업 현장에 적용하기에는 한계가 따랐다.
노타는 퀄컴의 최신 엣지 AI 디바이스인 ‘드래곤윙(Dragonwing™) IQ-9075’ 환경에서 VLA 모델인 ‘SmolVLA 0.45B’를 안정적으로 구동하는 데 성공했다. 이는 노타가 자체 기술력으로 모델 구조와 하드웨어 환경을 분석해 구동 환경을 독자 구축했다는 점에서 의미가 크다.
◇연산 그래프 최적화로 동작 생성 속도 7배↑…성공률은 유지
노타 연구진은 모델 전체를 무리하게 압축해 정확도를 떨어뜨리는 방식 대신, 속도 개선 효과를 극대화할 수 있는 구간을 타깃팅했다. VLA 모델의 전체 프로세스 중 앞단의 ‘인식·이해’ 단계는 그대로 유지하고, 실제 로봇의 움직임을 연산하는 마지막 ‘동작 생성(Action Head)’ 단계를 집중 공략한 것이다.
이를 위해 로봇 동작 생성 시 반복 연산을 대폭 줄이는 ‘실시간 추론 최적화(Real-time Inference Optimization)’ 기술과 퀄컴 디바이스 내 NPU(신경망처리장치) 실행 환경에 맞춘 ‘NPU 기반 그래프 최적화(NPU-aware Graph Optimization)’를 동시에 적용했다.
그 결과, 로봇 동작 생성 단계의 처리 시간은 기존 218ms(밀리초)에서 31ms로 무려 85.8% 감소했다. 연산 속도로 환산하면 최대 7배 빨라진 수치다. 전체 AI 추론 시간 역시 505ms에서 310ms로 크게 단축됐다. 반면 작업 성공률은 기존 86%에서 85%로 유사한 수준을 유지해, 속도를 비약적으로 끌어올리면서도 동작의 안정성은 완벽하게 확보했다는 평가다.
노타는 이번 최적화 성과를 미국 산타클라라에서 개최된 ‘임베디드 비전 서밋 2026(Embedded Vision Summit 2026)’에서 전격 공개했다.
현장 시연에서는 관람객이 직접 물품을 선택하면, 최적화된 VLA 모델이 실시간으로 이를 인식하고 로봇팔을 구동해 바구니에 담는 ‘체험형 데모’를 선보였다. 미리 정해진 영상을 재생하는 방식이 아닌, 현장 돌발 상황에 AI가 즉각 대응하는 실시간 구동을 완벽히 시연해 글로벌 테크 관계자들의 큰 호응을 얻었다.
노타는 이번 성과를 발판 삼아 스마트 제조, 지능형 공간, 자율주행 등 즉각적인 판단과 행동이 필요한 피지컬 AI 시장 선점에 속도를 낼 방침이다. 특히 퀄컴을 비롯한 글로벌 반도체 기업들과의 협력 생태계를 한층 강화해 온디바이스 AI 최적화 시장에서의 기술 격차를 선도하겠다는 전략이다.
노타 채명수 대표는 “피지컬 AI가 산업 현장으로 확산되기 위해서는 AI가 실제 환경을 보고, 이해하고, 행동으로 연결하는 과정을 엣지 AI 디바이스에서 빠르고 안정적으로 처리할 수 있어야 한다”며 “이번 VLA 최적화 성과는 노타의 AI 최적화 기술이 피지컬 AI 시대의 핵심 기반 기술로 확장될 수 있음을 보여준 의미 있는 사례”라고 말했다.









